GQL is a library created to make it easier to expose and consume GraphQL services.
1. Intro
GQL is a set of Groovy DSLs and AST transformations built on top of GraphQL-java to make it easier building GraphQL schemas and execute GraphQL queries without losing type safety.
GraphQL is a query language. It’s based in a type system and defines a specific query language and how a specific query engine should work in order to process and execute GraphQL queries.
| For a full detailed explanation about GraphQL I would recommend you to take a look at the official tutorial at http://graphql.org/learn/ |
Keeping long story short When dealing with GraphQL you normally will be following the these steps:
-
Define the schema (first types, scalars…and then adding those types to schema roots)
-
Expose the schema (via the chosen GraphQL implementation engine)
-
Execute queries against the implementation engine

Some of the ideas behind GQL:
-
It should be IDE friendly
-
It should be built having static compilation in mind
-
It should not need more than one import
2. Getting started
2.1. Hello GQL
This is how a full GraphQL life cycle app looks like using GQL:
@Grab('com.github.grooviter:gql-core:1.1.0')
import gql.DSL
def GraphQLFilm = DSL.type('Film') { (1)
field 'title', GraphQLString
field 'year', GraphQLInt
}
def schema = DSL.schema { (2)
queries {
field('lastFilm') {
type GraphQLFilm
staticValue(title: 'SPECTRE', year: 2015)
}
}
}
def query = """
{
lastFilm {
year
title
}
}
"""
def result = DSL.newExecutor(schema).execute(query) (3)
assert result.data.lastFilm.year == 2015
assert result.data.lastFilm.title == 'SPECTRE'| 1 | Creates a type GraphQLFilm |
| 2 | Creates a GraphQL schema using the previously defined types |
| 3 | Executes a GraphQL query string against the schema |
| You can execute the example as a Groovy script in the command line or using the Groovy console both available in any Groovy distribution. |
We have executed the query as a query string, however there is
a safer way of building queries using the DSL.query()` builder. It gives you some sanity checks based on the types
used.
|
2.2. Gradle
You can add the following dependency to your Gradle project
compile 'com.github.grooviter:gql-core:1.1.0'The library is available at Bintray so all you have to do is
to include the jcenter() declaration in your dependency repositories
in your Gradle script.
repositories {
mavenCentral()
}3. DSL
3.1. Types
Types define the structure of the data you want to expose. There two main sets of types, scalars and custom types. The former are specified by the GraphQL specification and are basic types such as strings, integers…etc whereas the latter refer to the types the developer will be defining (a Book, a Car…etc). We’ll make use of the scalars to build our own types.
3.1.1. Full types
In order to define a full type using GQL the only thing you have to do is to import gql.DSL and use the method
type:
import gql.DSL
def type = DSL.type('Droid') { (1)
description'simple droid' (2)
field('name') { (3)
description'name of the droid'
type GraphQLString
}
}| 1 | Defines a new type called Film |
| 2 | Adds a type description (useful to client users when exposing the schema) |
| 3 | Adds a field of type string (GraphQLString) |
The resulting type variable is an instance of graphql.schema.GraphQLObjectType.
We haven’t added the specific type to highlight the fact that no other import is needed. All basic scalar types such
as GraphQLString are defined within the DSL and both the compiler and the IDE should be able to recognize them.
|
You can add as many field('fieldName') { } blocks to your type as you want.
3.1.2. Shorter field definition
There is a shorter way of defining a given type. It’s specially useful when you’re prototyping or when you don’t care
about adding descriptions to your types. You can use the method field(String, Scalar) method within the type DSL.
The following example adds three different fields to the Droid type:
import gql.DSL
import graphql.schema.GraphQLObjectType
GraphQLObjectType type = DSL.type('Droid') {
field 'name', GraphQLString
field 'type', GraphQLString
field 'age', GraphQLInt
}3.1.3. Adding external fields
Sometimes you may want to keep type and field definitions apart, maybe to reuse those definitions, or maybe because it gives you more flexibility when structuring your app.
In the following example a field called name. It will always return its value in uppercase.
import gql.DSL
def nameToUpperCaseField = DSL.field('name') {
type GraphQLString
fetcher { DataFetchingEnvironment env ->
return "${env.source.name}".toUpperCase()
}
}Then we can use this definition in any type we want usign the addField method inside type DSL. In the example
every person’s name will be returned in uppercase.
import gql.DSL
def people = DSL.type('People') {
addField nameToUpperCaseField
addField ageMinusOne
}3.2. Scalars
GraphQL scalars represent the basic data types, such integers, strings, floats…. Although GraphQL comes with set of default scalar types, sometimes it will be handy to be capable to declare our own. In order to be able to handle that custom scalar type, we need to define how that scalar type will be serialized, and deserialized.
The following schema shows what is the path that a query execution follows from the query request until the scalar value has been serialized to send the response back to the client.

Now, when you define a Scalar what you’re doing is defining the deserialization functions:
-
parseLiteral: this function receives a query’s gql.ext.argument used as literal (as oppose as using a query variable) -
parseValue: this function receives a query’s gql.ext.argument used as a variable
You will also have to define the serialization method serialize which receives the result of executing a data
fetcher or from a static value and converts back the value to something meaningul to the client.
3.2.1. Declaration
When declaring a type you can set every field in it, and most of the time they will be whether built-in
scalars (GraphQLString or GraphQLFloat) or custom scalars like GraphQLPrice.
def orderType = DSL.type('Order') {
field 'subject', GraphQLString (1)
field 'units', GraphQLInt (2)
field 'price', GraphQLPrice (3)
}| 1 | subject: A string describing what is this order about |
| 2 | units: Number of items of this order |
| 3 | price: Unit price for each item |
The GraphQLPrice scalar has been defined as:
def GraphQLPrice = DSL.scalar('Price') { (1)
description 'currency unit' (2)
// deserialization
parseLiteral this::stringValueToMap (3)
parseValue this::stringValueToMap (4)
// serialization
serialize this::fromMapToString (5)
}| 1 | Setting scalar’s name |
| 2 | Setting scalar’s description (optional) |
| 3 | Setting parseLiteral function (optional) |
| 4 | Setting parseValue function (optional) |
| 5 | Setting serialize function (optional) |
Basically a scalar is a set of functions capable of deserializing a value, whether it’s coming from a literal (parseLiteral) or a variable value (parseValue), and serializing a value as a response to the initial request (serialize).
3.2.2. Deserialization
Literals
Now think of a situation where you want to set the price of a given product including the currency symbol, for instance
1.23Y. But of course it would be nice to have an automatic mechanism that keeps apart both number and symbol,
otherwise you could end up parsing that literal everywhere. So given the following query, which has a literal
containing a monetary concept:
def query = '''
{
order:changeOrderPrice(defaultPrice: "1.23Y") {
price
}
}
'''We want to keep the information, but contained in a map so that we could handle the number and the symbol separately.
For that we use the parseLiteral function.
def GraphQLPrice = DSL.scalar('Price') {
parseLiteral { money -> // 1.23Y
String value = money.value // from a StringValue
return [
unit: "$value"[0..-2].toDouble(), // 1.23
key: "$value"[-1..-1], // 'Y'
]
}
}The parseLiteral function will parse every literal of a Price scalar and it will separate the number from the
symbol and if you use a data fetcher, it will receive a map instead of the initial literal.
def schema = DSL.schema {
queries {
field('changeOrderPrice') {
type orderType
fetcher { env ->
// already converted :)
def price = env.arguments.defaultPrice // [unit: 1.23, key: 'Y']
[subject: 'paper', price: price]
}
argument 'defaultPrice', GraphQLPrice
}
}
}Variables
Literals are a easy and quick way of passing values to a query, but, if you wanted to reuse query strings you would want to use variables. And what happen if the value you want to convert is in a variable value ? Check this query:
def query = '''
query ChangeOrderPrice($price: Price){
order:changeOrderPrice(defaultPrice: $price) {
price
}
}
'''Now if look at the execution of the query:
def result = DSL
.newExecutor(schema)
.execute(query, [price: '1.25PTA'])Now how can I convert that string value coming from a variable to a map that I could receive in my data fetcher:
def scalar = DSL.scalar('Price') {
parseValue { String value -> // '1.25PTA'
return [
unit: value[0..-4].toDouble(), // 1.25
key: value[-1..-3].reverse(), // 'PTA'
]
}
}
parseLiteral parameters are simple Java parameters, not GraphQL node values as they were for the
parseLiteral function
|
Finally I can get the parsed value in the data fetcher:
def schema = DSL.schema {
queries {
field('changeOrderPrice') {
type orderType
fetcher { env ->
def price = env.arguments.defaultPrice // already converted :)
[subject: 'paper', price: price]
}
argument 'defaultPrice', scalar
}
}
}3.2.3. Serialization
We’ve been reviewing how to parse data coming from a query to something we can deal with. Serialization would be the opposite action, convert a given value produced by us into something meaninful to the client.
Following the same examples, we now the client is dealing with figures like: 1.23Y or 1.25PTA. But the problem
is that we’re producing tuples like: [unit:1.23, key: 'Y']. That cannot be rendered by the client, we need to convert
a given tuple to a meaninful literal with the serialize function.
def GraphQLPrice = DSL.scalar('Price') { (1)
description 'currency unit' (2)
// serialization
serialize { money -> // [unit: 1.23, key: '$'] (3)
"${money.unit}${money.key}" // "1.23$" (4)
}
}| 1 | Declaring the Price scalar type |
| 2 | Adding a description |
| 3 | Adding serialize function |
| 4 | Value return as response |
The function passed as an gql.ext.argument to the serialize method will take whatever value is coming from the data fetcher
or static value of the field and it will return the way you’d like to serialize that value to the client.
3.3. Enums
Also called Enums, enumeration types are a special kind of scalar that is restricted to a particular set of allowed
values. You can define a enum type with DSL.enum:
import gql.DSL
import graphql.schema.GraphQLEnumType
GraphQLEnumType CountryEnumType = DSL.enum('Countries') {
description 'european countries'
value 'SPAIN', 'es'
value 'FRANCE', 'fr'
value 'GERMANY', 'de'
value 'UK', 'uk'
}Then you can use that type as any other type for your type’s fields
import gql.DSL
import graphql.schema.GraphQLObjectType
GraphQLObjectType journey = DSL.type('Journey') {
field 'country', CountryEnumType
}3.4. Schemas
Once we’ve defined the structure of the data we want to expose, we need to define how that data is going to be retrieved. The schema defines:
-
Which types are exposed
-
How to interact with that data
Data is exposed as queries or mutations depending on whether the action is just a query or a request asking for creating/modifying data. Queries are declared as fields under the query node and mutations are also declared as fields under the mutation node:
import gql.DSL
import graphql.schema.GraphQLSchema
GraphQLSchema schema = DSL.schema {
queries { (1)
// no queries
}
mutations { (2)
field('insert') {
type filmType
fetcher { DataFetchingEnvironment env ->
def name = env.arguments.name
people << name
return [name: name]
}
argument 'name', GraphQLString
}
}
}| 1 | Queries |
| 2 | Mutations |
| Altough mutation node is optional, the query node is mandatory (could be empty but should be present) |
Both queries and mutations have a default name: Queries and Mutations respectively. But you
can pass a custom name if you want, for instance queries('CustomQueryRoot') { } or mutations('MutationRoot') { }
|
3.4.1. Static values
Sometimes you may want to expose constant values, values that are unlikely to change.
import gql.DSL
import graphql.schema.GraphQLSchema
GraphQLSchema schema = DSL.schema { (1)
queries('helloQuery') { (2)
description'simple droid'(3)
field('hello') { (4)
description'name of the droid'
type GraphQLString
staticValue 'world'
}
}
}| 1 | Declares a schema |
| 2 | Declares the query root node helloQuery |
| 3 | Adds a description to the helloQuery node |
| 4 | Declares a single query called hello which exposes a value world of type GraphQLString |
| In this example we are exposing just a single scalar value, but most of the time we will be exposing data through calls to underlying datastore engines. We’ll see how to do it in a bit. |
3.4.2. Fetchers
Most of the time we are fetching our data from a database, a micro-service, a csv file…etc and we normally use an API to query these datastores invoking some functions.
Now the same way we were able to expose static values using
the staticValue method in the DSL, we will be able to get data from a dynamic source via fetcher.
The gql.ext.argument of fetcher is an instance of type graphql.schema.DataFetcher:
package graphql.schema;
public interface DataFetcher<T> {
T get(DataFetchingEnvironment environment);
}Because DataFetcher is a
functional interface it is
possible to use the following options as arguments of the fetcher method:
-
A lambda/closure
-
A method reference/closure
-
An instance of an implementation of
DataFetcher
As a lambda/closure
The lambda expression or the closure receives a graphql.schema.DataFetchingEnvironment instance as parameter and
will return the requested data. The requested data should be of the same type of the declared type, or a map that
complies with the defined type.
import gql.DSL
import graphql.schema.GraphQLSchema
GraphQLSchema schema = DSL.schema {
queries('QueryRoot') {
description'queries over James Bond'
field('lastFilm') {
description'last film'
type filmType
fetcher(env -> [title: 'SPECTRE'])
// fetcher { env -> [title: 'SPECTRE']} <-- as a Closure
}
}
}As a method reference/closure
You can use either method closure or a Java’s method reference as a fetcher. The function should obey the signature
of the DataFetcher#get method (receiving a DataFetchingEnvironment as only parameter and returning an object of the
correct type).
import gql.DSL
import graphql.schema.GraphQLSchema
GraphQLSchema schema = DSL.schema {
queries('QueryRoot') {
description'queries over James Bond'
field('lastFilm') {
description'last film'
type filmType
fetcher Queries::findLastFilm
// fetcher Queries.&findLastFilm <-- method closure
}
}
}Environment
Is very important to be aware of this object because it holds information about the requested query, such as the arguments, the query types, extra information added to the fetcher context (it could be used to store user information for example)…etc.
In the following schema declaration, we are using a fetcher that eventually will need to get a year to be able to get the proper film:
import gql.DSL
import graphql.schema.GraphQLSchema
GraphQLSchema schema = DSL.schema {
queries {
field('byYear') {
type filmType
fetcher Queries.&findByYear
argument 'year', GraphQLString
}
}
}If we look to the method’s implementation, we’ll see how the DataFetchingEnvironment has a getArguments() method
returning a Map with the arguments values stored by their names:
import graphql.schema.DataFetchingEnvironment
static Map<String,?> findByYear(DataFetchingEnvironment env) {
String year = "${env.arguments.year}"
List<Map> dataSet = loadBondFilms()
Map<String,?> filmByYear = dataSet.find(byYear(year))
return filmByYear
}
The DataFetchingEnvironment object has a few more options that are worth knowing. I would recommend
you to take a look at the source code
here
|
3.5. Modularising
Modularising the way you create GraphQL schemas has at least a couple of benefits:
-
Enables you to write using plain GraphQL language: Writing code is cool, but you may be used to writing GraphQL schemas using the GraphQL language directly.
-
It allows you to separate parts of the schema by areas of interest: No more a huge single file declaring everything in one place
Lets say we have three different schema files in our classpath, and we would like to merge them all in order to create a sigle schema:
type Film {
title: String
}scalar CustomDate
type Band {
name: String
createdAt: CustomDate
}type Queries {
randomBand: Band
randomFilm: Film
}
schema {
query: Queries
}In this first example we will be using java.util.URI instances to locate our files, but as we will see later,
we can just use a java.lang.String to indicate where those files are within the application class loader.
URI uriOne = ClassLoader.getSystemResource('gql/dsl/bands.graphqls').toURI()
URI uriTwo = ClassLoader.getSystemResource('gql/dsl/films.graphqls').toURI()
URI uriTop = ClassLoader.getSystemResource('gql/dsl/qandm.graphqls').toURI()Then you can merge all of them. In this example we’ll only be mapping the query fields with the data fetchers needed to return some response.
import gql.DSL
GraphQLSchema proxySchema = DSL.mergeSchemas {
scalar(CustomDate)
byURI(uriOne) (1)
byURI(uriTwo)
byURI(uriTop) { (2)
mapType('Queries') { (3)
link('randomFilm') { DataFetchingEnvironment env -> (4)
return [title: 'Spectre']
}
link('randomBand') { DataFetchingEnvironment env ->
return [name: 'Whitesnake']
}
}
}
}| 1 | Merging schema fragment (only type definitions) |
| 2 | Merging another schema fragment but, this time, mapping inner types to some data fetchers |
| 3 | Declaring the interest to map some of the fields of type QueryType |
| 4 | Mapping a given data fetcher to field randomField |
And using just strings to indicate where the files are in the classpath:
import gql.DSL
GraphQLSchema proxySchema = DSL.mergeSchemas {
scalar(CustomDate)
byResource('gql/dsl/bands.graphqls')
byResource('gql/dsl/films.graphqls')
byResource('gql/dsl/qandm.graphqls') {
mapType('Queries') {
link('randomFilm') { DataFetchingEnvironment env ->
return [title: 'Spectre']
}
link('randomBand') { DataFetchingEnvironment env ->
return [name: 'Whitesnake']
}
}
}
}3.5.1. Custom Scalar implementation
If you’d like to add a custom scalar implementation when using the
modularization mechanism, you can do it from version
0.1.9-alpha. All you have to do is:
Declare the scalar in the schema:
scalar CustomDate
type Band {
name: String
createdAt: CustomDate
}Then create the scalar implementation with the Groovy DSL:
static GraphQLScalarType CustomDate = DSL.scalar('CustomDate') {
serialize { Date date ->
date.format('dd/MM/yyyy')
}
}And finally add the reference to the DSL.mergeSchemas body:
GraphQLSchema proxySchema = DSL.mergeSchemas {
scalar(CustomDate)
byResource('gql/dsl/bands.graphqls')
byResource('gql/dsl/films.graphqls')
byURI(schemaRootUri) {
mapType('Queries') {
link('randomBand') { DataFetchingEnvironment env ->
return [
name: 'Whitesnake',
createdAt: Date.parse('dd-MM-yyyy', '01-01-1977')
]
}
}
}
}3.5.2. Type resolvers
| If you’re using any of the GraphQL types that require a type resolver and you forgot to add it to the DSL, you will get a runtime exception. |
Interfaces
At some point you may want to create an interface as a base for other types.
interface Raffle {
id: String
title: String
names: [String]
}
type SimpleRaffle implements Raffle {
id: String
title: String
names: [String]
owner: String
}
type TwitterRaffle implements Raffle {
id: String
title: String
hashTag: String
names: [String]
}
type Queries {
raffles(max: Int): [Raffle]
}
schema {
query: Queries
}When using interfaces you need to provide a type resolver to make the GraphQL engine capable to decide when to return one type or another depending on the object return by the data fetcher.
void 'Apply a type resolver: interface (example)'() {
given: 'a schema'
GraphQLSchema proxySchema = DSL.mergeSchemas {
byResource('gql/dsl/Interfaces.graphqls') {
mapType('Queries') {
link('raffles') {
return [[title: 'T-Shirt', hashTag: '#greachconf']] (1)
}
}
mapType('Raffle') {
(2)
typeResolver { TypeResolutionEnvironment env ->
def raffle = env.getObject() as Map (3)
def schema = env.schema
return raffle.containsKey('hashTag') ?
schema.getObjectType('TwitterRaffle') : (4)
schema.getObjectType('SimpleRaffle')
}
}
}
}
and: 'a query with different type resolution'
def query = """{
raffles(max: 2) {
title
... on TwitterRaffle { (5)
hashTag
}
}
}
"""
when: 'executing the query against the schema'
def result = DSL.newExecutor(proxySchema).execute(query)
then: 'the result should have the type field'
result.data.raffles.every {
it.hashTag
}
}| 1 | The data fetcher returns a list of maps |
| 2 | Declaring a type resolver for type Raffle |
| 3 | The type resolver holds a reference of every item |
| 4 | The type resolver decides it is a TwitterRaffle if the map has a key hashTag otherwise it will be considered a SimpleRaffle |
| 5 | The query wants to get the information of a TwitterRaffle |
The typeResolver method could receive both a graphql.schema.TypeResolver instance or a Closure
keeping the contract of the TypeResolver functional interface like the example above.
Union Types
For union types the mechanism is the same. You only have to add a type resolver to the union type. Lets say we have the following schema:
interface Driver {
name: String
age: Int
team: String
}
type MotoGPDriver implements Driver {
name: String
age: Int
team: String
bike: String
}
type FormulaOneDriver implements Driver {
name: String
age: Int
team: String
engine: String
bodywork: String
}
union SearchResult = MotoGPDriver | FormulaOneDriver
type Queries {
searchDriversByName(startsWith: String): [SearchResult]
}
schema {
query: Queries
}There are both interfaces and union types, but the way we add a type resolver to any of them is just the same:
def schema = DSL.mergeSchemas {
byResource('gql/dsl/UnionTypes.graphqls') {
mapType('Driver') {
typeResolver(TypeResolverUtils.driversResolver())
}
mapType('SearchResult') {
typeResolver(TypeResolverUtils.driversResolver())
}
mapType('Queries') {
link('searchDriversByName', TypeResolverUtils.&findAllDriversByNameStartsWith)
}
}
}Then you can apply a query like the following:
def query = """{
searchDriversByName(startsWith: \"$driverName\") {
... on MotoGPDriver {
name
age
bike
}
... on FormulaOneDriver {
name
age
bodywork
}
}
}"""3.6. Inputs
Apart from using scalar values, like enums or string when passing arguments to a given query you can also easily pass complex objects. This is particularly valuable in the case of mutations, where you might want to pass in a whole object to be created. In GraphQL that means using input types.
Lets say we have a query to filter our mail inbox by from and to:
def query = '''
query QueryMail($filter: MailFilter) {
result: searchByFilter(filter: $filter) {
subject
}
}
'''We can model the MailFilter input type as:
GraphQLInputObjectType MailFilterType = DSL.input('MailFilter') {
field 'from', GraphQLString
field 'to', GraphQLString
}And finally when executing the query we can pass a map with the mail filter values.
ExecutionResult result = DSL
.newExecutor(schema)
.execute(query, [filter: [from: 'me@somedomain.com', to: 'you@somedomain.com']])3.6.1. Arguments
Input types can only be used as an argument of a query or a mutation. Therefore when
declaring a given mutation, you can say that the argument of that query or mutation
can be of input type X:
GraphQLSchema schema = DSL.schema {
queries {
field('searchByFilter') {
type list(MailResult)
argument 'filter', MailFilterType // --> input type
fetcher { DataFetchingEnvironment env ->
assert env.arguments.filter.from == 'me@somedomain.com'
assert env.arguments.filter.to == 'you@somedomain.com'
return [[subject: 'just this email here!']]
}
}
}
}4. Execution
This chapter explains how to execute GraphQL queries using GQL.
4.1. Executor
4.1.1. From a schema
In order to execute any GraphQL query first you need to get an instance of an GraphQLExecutor
import gql.DSL
GraphQLExecutor executor = DSL.newExecutor(schema)Once you have an executor you can reuse it to execute as many queries as you like without incurring in performance issues.
def result1 = executor.execute query1
def result2 = executor.execute query2
...4.2. Simple query execution
Once you’ve got an instance of GraphQLExecutor you can execute a query:
import gql.DSL
GraphQLExecutor executor = DSL.newExecutor(schema) (1)
String query1 = '''
{
movies {
title
}
}
'''
ExecutionResult result = executor.execute(query1) (2)
Map<String, ?> data = result.data (3)
List<?> errors = result.errors (4)| 1 | Creating an instance of GraphQLExecutor |
| 2 | The result of executing a query is a graphql.ExecutionResult |
| 3 | The result could contain some data |
| 4 | Or could contain GraphQL errors |
4.3. Passing arguments
In order to execute a given query with arguments you can use GraphQLExecutor#execute(string, variables):
def queryString = '''
query FindBondByYear($year: String) {
byYear(year: $year) {
year
title
}
}
'''def result = DSL.newExecutor(schema).execute(queryString, [year: "1962"])4.4. Async Execution
GQL through graphql-java can use fully asynchronous execution when
executing queries. You can get a
java.util.concurrent.CompleteableFuture of an ExecutionResult by
calling GraphQLExecutor#executeAsync() like this:
CompletableFuture<ExecutionResult> result = DSL
.newExecutor(schema)
.executeAsync(" { getName } ")If a data fetcher returns a CompletableFuture<T> object then this will be composed into the overall asynchronous query execution. This means you can fire off a number of field fetching requests in parallel. Exactly what threading strategy you use is up to your data fetcher code.
4.5. Query builders
GQL allows you to execute queries directly or to build them to use them later via DSL builder. The former is useful if you already have the queries and you are sure they work as expected. The latter is a safer way of building queries because it gives you some sanity checks based on the types used.
4.5.1. Execute queries
If you’re using the underlying GQL GraphQL engine to execute your queries, it would be nice to be able to declare and execute queries in one shot right ?
import gql.DSL
import graphql.ExecutionResult
import graphql.GraphQL
import graphql.execution.instrumentation.SimpleInstrumentation
import graphql.execution.instrumentation.tracing.TracingInstrumentation
import graphql.schema.DataFetchingEnvironment
import graphql.schema.GraphQLType
ExecutionResult result = DSL.newExecutor(schema).execute {
query('byYear', [year: '1962']) { (1)
returns(Film) { (2)
title
year
}
alias 'first' (3)
}
}| 1 | Defines a query with name byYear mapping query parameters |
| 2 | Checks that the fields used in the close are present in type Film. Uses static check to make sure fields are
present in type Film |
| 3 | Defines a given alias to the query result |
import gql.DSL
import graphql.ExecutionResult
import graphql.GraphQL
import graphql.execution.instrumentation.SimpleInstrumentation
import graphql.execution.instrumentation.tracing.TracingInstrumentation
import graphql.schema.DataFetchingEnvironment
import graphql.schema.GraphQLType
ExecutionResult result2 = DSL.newExecutor(schema).execute {
query('byYear', [year: '2015']) { (1)
returns { (2)
title
year
bond
}
alias 'last' (3)
}
}| 1 | Defines a query with name lastFilm mapping variables |
| 2 | Declares a set of fields but are not checked |
| 3 | Defines a given alias to the query result |
4.5.2. Query string
Sometimes your exposed GraphQL schema may be backed up by another third party GraphQL engine implementation, but instead of writing or queries by hand we still may want to use the DSL to build the query and then use the resulting string against the other engine.
import gql.DSL
String queryString = DSL.buildQuery {
query('byYear', [year: '1962']) {
returns(Film) {
title
year
}
alias 'first'
}
query('byYear', [year: '2015']) {
returns {
title
year
bond
}
alias 'last'
}
}4.5.3. Nested queries
From version 1.1.0 you can create nested queries:
import gql.DSL
String queryString = DSL.buildQuery {
query('searchOrders', [filter: [status: 'ACTIVE']]) {
returns(Order) {
id
status
query('entries', [first: 2]) {
returns(OrderEntry) {
id
subject
count
price
}
}
}
}
}4.5.4. Mutation string
Of course apart from queries you may want to execute mutations.
import gql.DSL
String mutation = DSL.buildMutation {
mutation('saveOrder', [order: order]) {
returns(Order) {
id
status
}
}
}Nesting also works for mutations:
import gql.DSL
String mutation = DSL.buildMutation {
mutation('saveOrder', [order: order]) {
returns(Order) {
id
status
query('entries', [first: 2]) {
returns(OrderEntry) {
id
subject
count
price
}
}
}
}
}4.6. Exposing GraphQL
4.6.1. From GraphQLExecutor
From any gql.dsl.executor.GraphQLExecutor you can get the underlying graphql.GraphQL instance:
GraphQLExecutor executor = DSL.newExecutor(schema)
ExecutionResult result = executor.graphQL.execute("{ getName }")4.6.2. Directly from DSL
Because GQL can’t think on every single case, there’s a chance somebody may miss to access to the graphql-java
low level API.
GraphQL graphQL = DSL.newGraphQLBuilder(schema).build()Or if you’d like to initialize it with some options:
GraphQL.Builder builder = DSL.newGraphQLBuilder(schema) {
withInstrumentation(new SimpleInstrumentation())
}5. Relay
5.2. What GQL implements ?
According to the Relay official site, the three core assumptions that Relay makes about a GraphQL server are that it provides:
-
A mechanism for refetching an object.
-
A description of how to page through connections.
-
Structure around mutations to make them predictable.
Relay uses GraphQL as its query language, but it is not tied to a specific implementation of GraphQL. In order to achieve these three goals, the Relay specification defines three conceps: Node, Connection, Edges.
You can think of the relationship between the three terms looking at this diagram:
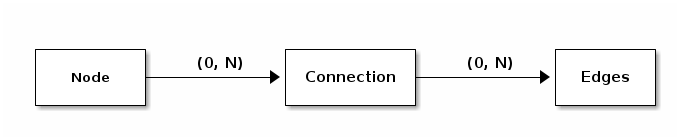
A Node may have a Connection and a Connection may have 0 to N Edges. Lets see what these terms mean.
5.3. Node
A Node is a type that can be retrieved by an unique identifier. Therefore a node always has an id field.
Apart from the id field, a node can have more fields. However there’s a special type of node field called connection. A Connection is a type of fields mapping one-to-many relationships. Here’s an example on how to declare a new node:
GraphQLOutputType Faction = Relay.node('Faction') { (1)
description 'party spirit especially when marked by dissension'
field 'name', GraphQLString
field 'ships', ShipConnection (2)
}| 1 | Node description |
| 2 | Fields |
| You don’t have to declare the id field. GQL has already added for you every time you declare a node type. |
Although you can always declare a connection as a normal field and build the connection type via the DSL.connection()
method, you can do it directly in the DSL like this:
GraphQLOutputType Faction = Relay.node('Faction') {
field 'name', GraphQLString (1)
connection('ships') { (2)
type ShipConnection
listFetcher { (3)
Integer limit = it.getArgument('first')
return SHIPS.take(limit)
}
}
}| 1 | Declaring a normal field |
| 2 | Declaring a connection with connection edges' nodes of type Ship |
| 3 | Declaring a special fetcher to get the result |
5.3.1. listFetcher
To fetch the content of a connection field you can always use a simple data fetcher, but because a Connection field has always some repetitive meta data, GQL has abstracted the way that metadata is created.
All you have to do is to make the listFetcher { } invocation to return a list of the edge items, then GQL will took
over and it will fulfill the information relative to pageInfo and edges.
5.4. Connection
A Connection is just a convention on how to access one-to-many relationships in a node, and how to paginate through those items. A Connection has two fields:
-
pageInfo: information regarding on how to paginate through the edges.
-
edges: a collection of result items.
Every edge has two fields:
-
cursor: identifies where in the pagination cursor is the edge located
-
node: the edge payload
GraphQLOutputType ShipConnection = Relay.connection('ShipConnection') { (1)
edges('Ship') { (2)
description 'a starship'
field 'name', GraphQLString
}
}| 1 | Declaring a connection type |
| 2 | Declaring the type of the connection’s edge items |
5.5. Full Example
In this example we would like to get a certain number of the ships of the rebel faction.
def query = """
{
rebels {
name
ships(first: $noResults) {
pageInfo {
hasNextPage
}
edges {
cursor
node {
name
}
}
}
}
}
"""So first thing to do is to declare the Faction type:
GraphQLOutputType Faction = Relay.node('Faction') {
field 'name', GraphQLString (1)
connection('ships') { (2)
type ShipConnection
listFetcher { (3)
Integer limit = it.getArgument('first')
return SHIPS.take(limit)
}
}
}| 1 | A faction has a name |
| 2 | A faction has ships which is a one-to-many relationship |
| 3 | Data fetcher |
The Node types can declare a special type of fetcher, the listFetcher. That call can convert the result of a simple function returning a list to a Connection type.
To declare a connection type you can use Relay.connection. In this example we’re declaring edges of type ShipEdges which have nodes of type Ship.
Every edge item will have two fields: node which is every item of the relationship, and a cursor which is a hash locating every edge in the relationship, it could be taken as if it were a kind of offset.
GraphQLOutputType ShipConnection = Relay.connection('ShipConnection') { (1)
edges('Ship') { (2)
description 'a starship'
field 'name', GraphQLString
}
}And finally declare the schema:
GraphQLSchema schema = Relay.schema {
queries {
field('rebels') {
type Faction
fetcher {
return [id: 'RmFjdGlvbjox', name: 'Alliance to Restore the Republic']
}
}
}
}Now when executing the query, that’s how the execution flow will be:

6. Ratpack
Ratpack http://ratpack.io is a set of Java libraries for building scalable HTTP applications. You can use Ratpack to make a given GraphQL schema available through HTTP.
6.1. Example
Here is a minimum Groovy working example of a GraphQL schema exposed through HTTP thanks to Ratpack.
@Grab('com.github.grooviter:gql-ratpack:1.0.0')
import static ratpack.groovy.Groovy.ratpack
import gql.DSL
import gql.ratpack.GraphQLModule
import gql.ratpack.GraphQLHandler
import gql.ratpack.GraphiQLHandler
def schema = DSL.schema { (1)
queries('Queries') {
field('hello') {
type GraphQLString
staticValue 'GraphQL and Groovy!'
}
}
}
ratpack {
bindings {
module GraphQLModule (2)
bindInstance schema (3)
}
handlers {
post('graphql', GraphQLHandler) (4)
get('graphql/browser', GraphiQLHandler) (5)
}
}| 1 | Create the schema using gql.DSL api |
| 2 | Add the gql.ratpack.GraphQLModule in order to provide sane defaults to handlers and GraphiQL configuration |
| 3 | Add the schema to Ratpack’s registry |
| 4 | Register the GraphQLHandler to handle all GrahpQL request at /graphql |
| 5 | Register the GraphiQLHandler to be able to expose GraphiQL client at /graphql/browser. |
6.2. Execution context
GQL Ratpack integration exposes the Ratpack’s handle context as the
via the extension module adding the DataFetchingEnvironment#getRatpackContext() method.
import ratpack.handling.Context
import graphql.schema.DataFetchingEnvironment
def schema = DSL.schema {
queries('Queries') {
field('hello') {
type GraphQLString
dataFetcher { DataFetchingEnvironment env ->
// Context context = env.context as Context --> Deprecated
Context context = env.ratpackContext
return context
.header('Authorization') (1)
.map { 'GraphQL and Groovy' } (2)
.orElse 'Unauthorizated' (3)
}
}
}
}| 1 | Takes content from header Authorization |
| 2 | If it had a value it returns a positive message |
| 3 | Otherwise informs the user is not authorized |
Having the possibility of accessing Ratpack’s context could be useful for things like:
-
Authentication
-
Authorization
-
Logging
-
…
You could also be able to access the context through instrumentation.
6.3. GraphQL errors
gql-java catches exceptions thrown while executing data fetchers and
shows their information along with the stack trace as output.
The problem is that errors can’t be thrown and the only way to propagate them when executing a data fetcher is via a data fetcher instrumentation.
class SecurityInstrumentation extends SimpleInstrumentation {
@Override
DataFetcher<?> instrumentDataFetcher(
DataFetcher<?> dataFetcher,
InstrumentationFieldFetchParameters parameters,
InstrumentationState state
) {
String user = parameters.environment.contextAsMap.user?.toString()
if (user) {
return dataFetcher
}
ResultPath path = parameters
.getEnvironment()
.executionStepInfo
.getPath()
GraphQLError error = DSL.error {
message 'No user present'
extensions(i18n:'error.not.present')
}
parameters
.getExecutionContext()
.addError(error, path)
return { env -> } as DataFetcher
}
}You can create a GraphQLError using DSL.error. But if what you
want to create is a fetcher adding an error to the current execution
context, this could be improved using DSL.errorFetcher:
package gql.ratpack
import graphql.execution.instrumentation.InstrumentationState
import graphql.execution.instrumentation.SimpleInstrumentation
import graphql.schema.DataFetcher
import graphql.execution.instrumentation.parameters.InstrumentationFieldFetchParameters
import gql.DSL
class SecurityChecker extends SimpleInstrumentation {
@Override
DataFetcher<?> instrumentDataFetcher(
DataFetcher<?> dataFetcher,
InstrumentationFieldFetchParameters parameters,
InstrumentationState state
) {
return parameters
.environment
.ratpackContext
.header('Authorization')
.map { dataFetcher }
.orElse(DSL.errorFetcher(parameters) {
message 'security'
extensions(i18n: 'error.security.authorization')
})
}
}In the previous example if there’s no Authorization header then an
error will be shown in the response, otherwise the expected data
fetcher will take over the execution.
6.4. Instrumentation
Following graphql-java documentation The
graphql.execution.instrumentation.Instrumentation interface allows you
to inject code that can observe the execution of a query and also
change the runtime behaviour.
The gql-ratpack makes possible to add a given instance of type
graphql.execution.instrumentation.Instrumentation to the registry
and that instance will be used by the current execution.
If you’d like to use more than one instrumentation then you may create
an instance of
graphql.execution.instrumentation.ChainedInstrumentation and add all
other instrumentation instances to it, context will be passed through
the chained instrumentation to all children.
6.5. Configuration
If you would like to disable the GraphiQL client, you can always configure the
GraphQLModule setting the activateGraphiQL to false.
ratpack {
bindings {
module(GraphQLModule) { conf ->
conf.activateGraphiQL = false (1)
}
//...
}
handlers {
//...
}
}| 1 | Setting the activateGraphiQL to false will disable GraphiQL client |
6.6. Futures.async/blocking
Ratpack’s execution model requires that all blocking operations are done in the blocking executor. Because one of the natural return types of a data fetcher could be a CompletableFuture, we could use that type as long as it is executed in the right executor.
To make this easier, from version 0.3.1 there is gql.ratpack.exec.Futures
which creates a blocking CompletableFuture instances Futures.blocking or
non blocking Futures.async using Ratpack’s correct executors.
import ratpack.handling.Context
import graphql.schema.DataFetchingEnvironment
import gql.ratpack.exec.Futures
def schema = DSL.schema {
queries('Queries') {
field('hello') {
type GraphQLString
dataFetcher { DataFetchingEnvironment env ->
Futures.blocking {
// do something in the blocking executor
}
}
}
}
}6.7. Pac4j
Although you can create your own authentication mechanisms
using instrumentations, it’s also true that you can use already existent HTTP
authentication mechanisms. A good example could be Pac4j integration with
Ratpack.
@Grab('com.github.grooviter:gql-ratpack:1.0.0')
import static ratpack.groovy.Groovy.ratpack
import gql.DSL
import gql.ratpack.GraphQLModule
import gql.ratpack.pac4j.GraphQLHandler
def schema = DSL.schema { (1)
queries('Queries') {
field('hello') {
type GraphQLString
fetcher { env ->
UserProfile profile = env.ratpackContext.request.get(UserProfile)
return profile ? "You pass" : "You shall not pass!"
}
}
}
}
ratpack {
bindings {
module GraphQLModule
bindInstance schema
}
handlers {
post('graphql', GraphQLHandler)
}
}7. Development
7.1. Source code
Source code is available at https://github.com/grooviter/gql
7.2. Groovydoc
Groovy API is available at https://grooviter.github.io/gql/api/index.html